ViT는 가장 간단한 유형의 변압기입니다.
실제로 구현하는 것은 그리 어렵지 않습니다.
하지만……….
학위 논문에 따르면 ViT는 “대규모 사전 교육” 없이는 성능이 훨씬 더 나쁩니다.
즉, 시간이 오래 걸리고 귀찮습니다.
다행히 나만 걱정한 게 아니라 천조국 형들도 걱정했다.
누군가 이미 라이브러리로 만들었습니다.
그것으로 모델을 만들어 봅시다.
일단 설치
pip install timm
그리고 OOP로 작성된 코드는 다음과 같습니다.
(장치는 macbook의 경우 mps, Windows의 경우 cuda입니다)
import timm
import torch
import torchvision
import torch.utils.data as data
import torchvision.transforms as transforms
device="mps"
# device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
BATCH_SIZE = 100
NUM_WORKERS = 2
transform = transforms.Compose((
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225))
))
test_set = torchvision.datasets.ImageFolder('./data/ImageNet/val', transform=transform)
test_loader = data.DataLoader(test_set, batch_size=BATCH_SIZE, shuffle=True, num_workers=NUM_WORKERS)
class ViTImageNet21k(object):
def __init__(self):
self.model = None
def process(self):
self.build_modeL()
self.eval_model()
def build_modeL(self):
self.model = timm.models.vit_base_patch16_224(pretrained=True).to(device)
# self.model = timm.models.vit_large_patch16_224(pretrained=True).to(device)
print(f'Parameter : {sum(p.numel() for p in self.model.parameters() if p.requires_grad)}')
def eval_model(self):
model = self.model
model.to(device).eval()
correct_top1 = 0
correct_top5 = 0
total = 0
with torch.no_grad():
for idx, (images, labels) in enumerate(test_loader):
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, pred = torch.max(outputs, 1)
total += labels.size(0)
correct_top1 += (pred == labels).sum().item()
_, rank5 = outputs.topk(5, 1, True, True)
rank5 = rank5.t()
correct = rank5.eq(labels.view(1, -1).expand_as(rank5))
for k in range(6):
correct_k = correct(:k).reshape(-1).float().sum(0, keepdim=True)
correct_top5 += correct_k.item()
print(f"Step : {idx + 1} / {int(len(test_set) / int(labels.size(0)))}")
print(f"top-1 Accuracy : {correct_top1 / total * 100:0.2f}%")
print(f"top-5 Accuracy : {correct_top5 / total * 100:0.2f}%")
print(f"top-1 Accuracy : {correct_top1 / total * 100:0.2f}%")
print(f"top-5 Accuracy : {correct_top5 / total * 100:0.2f}%")
if __name__ == "__main__":
ViTImageNet21k().process()이제 ImageNet 데이터 세트를 가져와서 실행해야 합니다.
(이게 진짜 왕이다^^)
이미지넷 공식 홈페이지
https://image-net.org/download-images
이미지넷
ImageNet 데이터 다운로드 ImageNet은 이미지에 대한 저작권을 소유하지 않습니다. 비상업적 연구 및/또는 교육 목적으로 이미지를 사용하려는 연구원 및 교육자를 위해 당사는 특정 조건 하에서 당사 웹사이트를 통해 액세스 권한을 부여할 수 있습니다.
image-net.org
기입
회원 가입
학교 이메일 주소(ac.kr로 끝남) 사용을 권장합니다.
별표가 없는 항목은 모두 작성해야 합니다.
신청 버튼이 나타나면 클릭하고 확인 이메일로 이동합니다.
지금 다운로드할 수 있습니다.

아래에서 유효성 검사 이미지를 얻을 수 있습니다.
다운로드한 파일(tar 확장자)을 ./data/ImageNet/ 폴더에 넣습니다.
./data/ImageNet/ 폴더에서 터미널을 엽니다.
mkdir val && mv ILSVRC2012_img_val.tar val/ && cd val && tar -xvf ILSVRC2012_img_val.tar
wget -qO- https://raw.githubusercontent.com/soumith/imagenetloader.torch/master/valprep.sh | bash입력하면 압축이 풀리고 val 폴더가 생성됩니다.
tar 확장 파일을 삭제할 수 있습니다.
이제 위의 코드를 실행하면 다시 나타납니다.
배치(100개 이미지)에 대한 정확도가 나오는 것을 볼 수 있습니다.
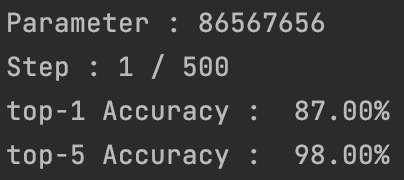
논문에서는 상위 1: 84.44%, 상위 5: 97.25가 나와야 합니다.
50,000개 다 하면 나올 것 같아요.
끝.